Smoothing Baselines
Introduction
Smoothing algorithms use moving-window based smoothing operations such as moving averages, moving medians, and Savitzky-Golay filtering to eliminate peaks and leave only the baseline.
Note
The window size used for smoothing-based algorithms is index-based, rather than based on the units of the data, so proper conversions must be done by the user to get the desired window size.
Algorithms
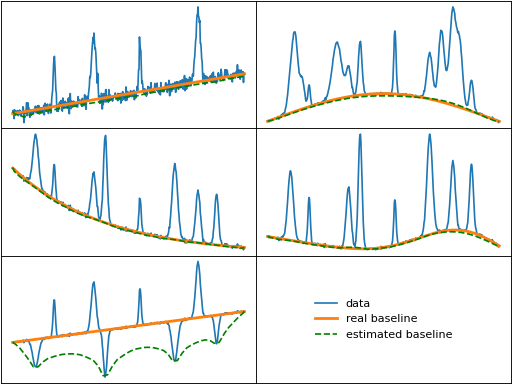
noise_median (Noise Median method)
noise_median() estimates the baseline as the median value within
a moving window. The resulting baseline is then smoothed by convolving with a Gaussian
kernel. Note that this method does not perform well for tightly-grouped peaks.
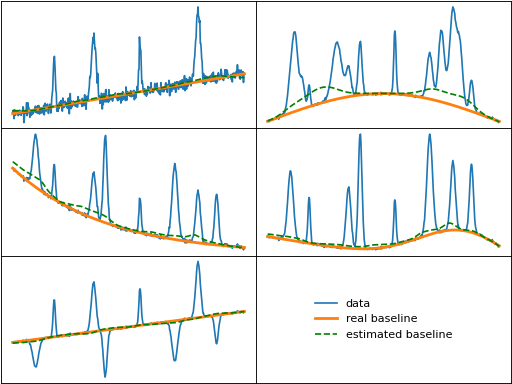
snip (Statistics-sensitive Non-linear Iterative Peak-clipping)
snip() iteratively takes the element-wise minimimum of each value
and the average of the values at the left and right edge of a window centered
at the value. The size of the half-window is incrementally increased from 1 to the
specified maximum size, which should be set to approximately half of the
index-based width of the largest peak or feature.
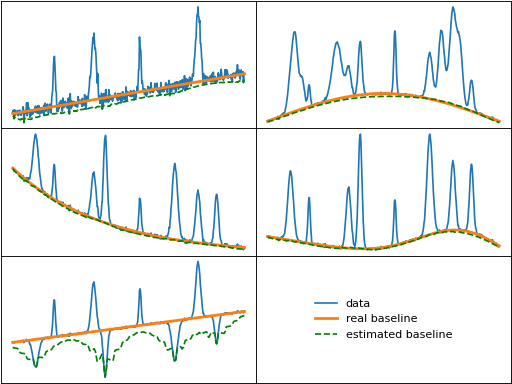
A smoother baseline can be obtained from the snip function by setting decreasing
to True, which reverses the half-window size range to start at the maximum size and end at 1.
Further, smoothing can optionally be performed to make the baseline better fit noisy
data. The baselines when using decreasing window size and smoothing is shown below.
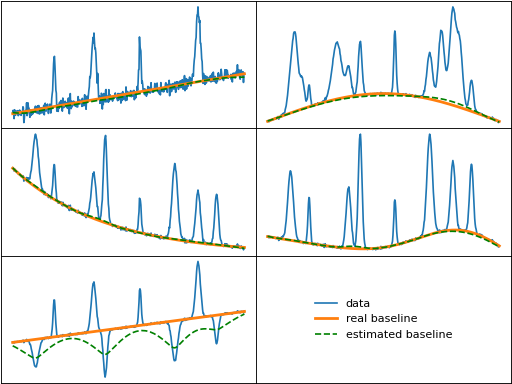
swima (Small-Window Moving Average)
swima() iteratively takes the element-wise minimum of either the
data (first iteration) or the previous iteration's baseline and the data/previous baseline
smoothed with a moving average. The window used for the moving average smoothing is
incrementally increased to smooth peaks until convergence is reached.
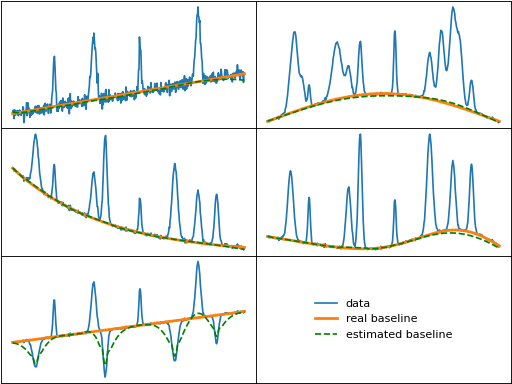
ipsa (Iterative Polynomial Smoothing Algorithm)
ipsa() iteratively smooths the input data using a second-order
Savitzky–Golay filter until the exit criteria is reached.
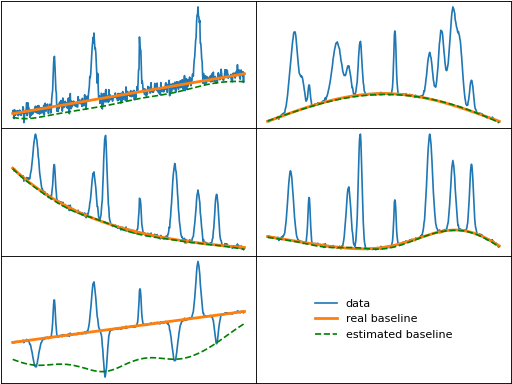
ria (Range Independent Algorithm)
ria() first extrapolates a linear baseline from the left and/or
right edges of the data and adds Gaussian peaks to these baselines, similar to the
optimize_extended_range function, and
records their initial areas. The data is then iteratively smoothed using a
zero-order Savitzky–Golay filter (moving average) until the area of the extended
regions after subtracting the smoothed data from the initial data is close to
their starting areas.
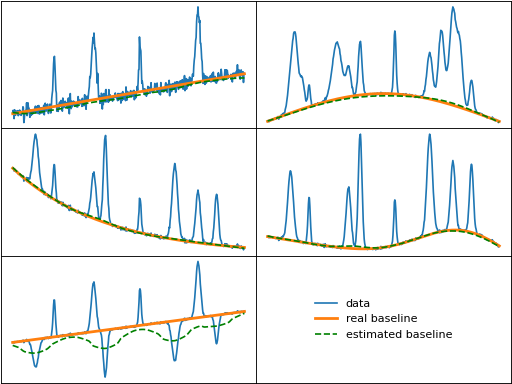
peak_filling (4S Peak Filling Algorithm)
peak_filling() performs four "S" steps: smooth, subsample, suppress,
and stretch. In detail, the method smooths and truncates the input. Each value is then
replaced in-place by the minimum of the value or the average of the moving window, with
the half-window size decreasing exponentially from the input half_window to 1. The result
is then interpolated back into the original data size.