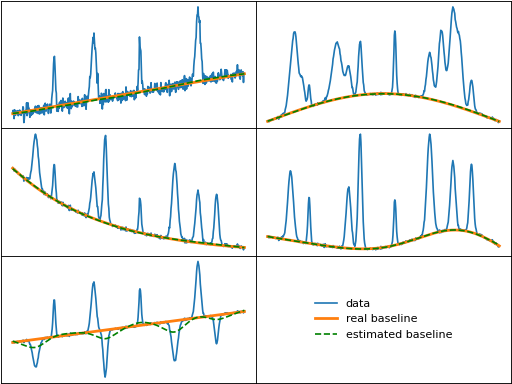
Whittaker Baselines
Introduction
Whittaker-smoothing-based algorithms are usually referred to in literature
as weighted least squares, penalized least squares, or asymmetric least squares,
but are referred to as Whittaker-smoothing-based in pybaselines to distinguish them from polynomial
techniques that also take advantage of weighted least squares (like loess())
and penalized least squares (like penalized_poly()).
A great introduction to Whittaker smoothing is Paul Eilers's A Perfect Smoother paper (note that Whittaker smoothing is often also referred to as Whittaker-Henderson smoothing and as Hodrick-Prescott filtering in the case of a second order difference). The general idea behind Whittaker smoothing algorithms is to make the baseline match the measured data as well as it can while also penalizing the roughness of the baseline. The resulting general function that is minimized to determine the baseline is then
where \(y_i\) is the measured data, \(v_i\) is the estimated baseline, \(\lambda\) is the penalty scale factor, \(w_i\) is the weighting, and \(\Delta^d\) is the finite-difference operator of order d.
The resulting linear equation for solving the above minimization is:
where \(W\) is the diagaonal matrix of the weights, and \(D_d\) is the matrix version of \(\Delta^d\), which is also the d-th derivative of the identity matrix. For example, for an array of length 5, \(D_1\) (first order difference matrix) is:
and \(D_2\) (second order difference matrix) is:
Most Whittaker-smoothing-based techniques recommend using the second order difference matrix, although some techniques use both the first and second order difference matrices.
The baseline is iteratively calculated using the linear system above by solving for the baseline, \(v\), updating the weights, solving for the baseline using the new weights, and repeating until some exit criteria. The difference between Whittaker-smoothing-based algorithms is the selection of weights and/or the function that is minimized.
Note
The \(\lambda\) (lam) value required to fit a particular baseline for all
Whittaker-smoothing-based methods will increase as the number of data points increases, with
the relationship being roughly \(\log(\lambda) \propto \log(\text{number of data points})\).
For example, a lam value of \(10^3\) that fits a dataset with 100 points may have to
be \(10^7\) to fit the same data with 1000 points, and \(10^{11}\) for 10000 points.
Algorithms
asls (Asymmetric Least Squares)
The asls() (sometimes called "ALS" in literature) function is the
original implementation of Whittaker smoothing for baseline fitting.
Minimized function:
Linear system:
Weighting:

iasls (Improved Asymmetric Least Squares)
iasls() is an attempt to improve the asls algorithm by considering
both the roughness of the baseline and the first derivative of the residual
(data - baseline).
Minimized function:
Linear system:
Weighting:

airpls (Adaptive Iteratively Reweighted Penalized Least Squares)
airpls() uses an exponential weighting of the negative residuals to
attempt to provide a better fit than the asls method.
Minimized function:
Linear system:
Weighting:
where \(t\) is the iteration number and \(|\mathbf{r}^-|\) is the l1-norm of the negative values in the residual vector \(\mathbf r\), ie. \(\sum\limits_{y_i - v_i < 0} |y_i - v_i|\). Note that the absolute value within the weighting was mistakenly omitted in the original publication, as specified by the author.

arpls (Asymmetrically Reweighted Penalized Least Squares)
arpls() uses a single weighting function that is designed to account
for noisy data.
Minimized function:
Linear system:
Weighting:
where \(r_i = y_i - v_i\) and \(\mu^-\) and \(\sigma^-\) are the mean and standard deviation, respectively, of the negative values in the residual vector \(\mathbf r\).
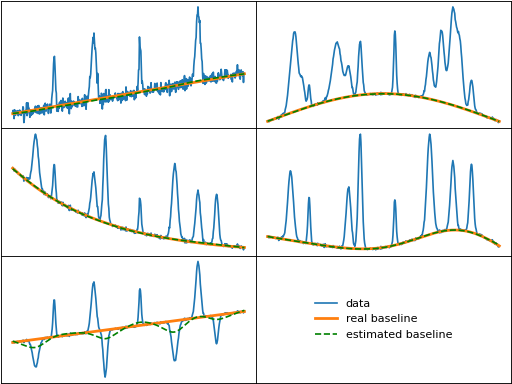
drpls (Doubly Reweighted Penalized Least Squares)
drpls() uses a single weighting function that is designed to account
for noisy data, similar to arpls. Further, it takes into account both the
first and second derivatives of the baseline and uses a parameter \(\eta\)
to adjust the fit in peak versus non-peak regions.
Minimized function:
where \(\eta\) is a value between 0 and 1 that controls the effective value of \(\lambda\).
Linear system:
where \(I\) is the identity matrix.
Weighting:
where \(r_i = y_i - v_i\), \(t\) is the iteration number, and \(\mu^-\) and \(\sigma^-\) are the mean and standard deviation, respectively, of the negative values in the residual vector \(\mathbf r\).
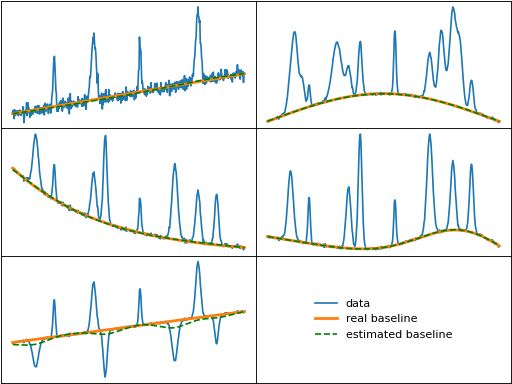
iarpls (Improved Asymmetrically Reweighted Penalized Least Squares)
iarpls() is an attempt to improve the arpls method, which has a tendency
to overestimate the baseline when fitting small peaks in noisy data, by using an
adjusted weighting formula.
Minimized function:
Linear system:
Weighting:
where \(r_i = y_i - v_i\), \(t\) is the iteration number, and \(\sigma^-\) is the standard deviation of the negative values in the residual vector \(\mathbf r\).

aspls (Adaptive Smoothness Penalized Least Squares)
aspls(), similar to the iarpls method, is an attempt to improve the arpls method,
which it does by using an adjusted weighting function and an additional parameter \(\alpha\).
Minimized function:
where
Linear system:
Weighting:
where \(r_i = y_i - v_i\), \(\sigma^-\) is the standard deviation of the negative values in the residual vector \(\mathbf r\), and \(k\) is the asymmetric coefficient (Note that the default value of \(k\) is 0.5 in pybaselines rather than 2 in the published version of the asPLS. pybaselines uses the factor of 0.5 since it matches the results in Table 2 and Figure 5 of the asPLS paper closer than the factor of 2 and fits noisy data much better).

psalsa (Peaked Signal's Asymmetric Least Squares Algorithm)
psalsa() is an attempt at improving the asls method to better fit noisy data
by using an exponential decaying weighting for positive residuals.
Minimized function:
Linear system:
Weighting:
where \(k\) is a factor that controls the exponential decay of the weights for baseline values greater than the data and should be approximately the height at which a value could be considered a peak.
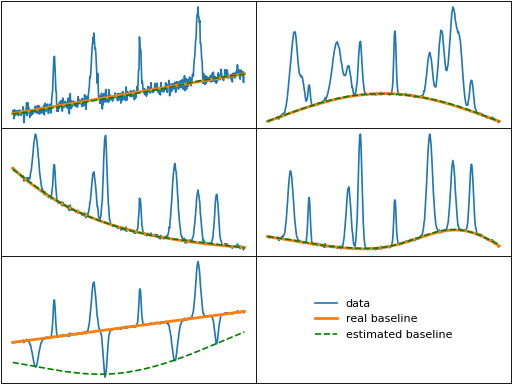
derpsalsa (Derivative Peak-Screening Asymmetric Least Squares Algorithm)
derpsalsa() is an attempt at improving the asls method to better fit noisy data
by using an exponential decaying weighting for positive residuals. Further, it calculates
additional weights based on the first and second derivatives of the data.
Minimized function:
Linear system:
Weighting:
where:
\(k\) is a factor that controls the exponential decay of the weights for baseline values greater than the data and should be approximately the height at which a value could be considered a peak, \(y_{sm}'\) and \(y_{sm}''\) are the first and second derivatives, respectively, of the smoothed data, \(y_{sm}\), and \(rms()\) is the root-mean-square operator. \(w_1\) and \(w_2\) are precomputed, while \(w_0\) is updated each iteration.

brpls (Bayesian Reweighted Penalized Least Squares)
brpls() calculates weights by considering the probability that each
data point is part of the signal following Bayes' theorem.
Minimized function:
Linear system:
Weighting:
where:
\(r_i = y_i - v_i\), \(\beta\) is 1 minus the mean of the weights of the previous iteration, \(\sigma^-\) is the root mean square of the negative values in the residual vector \(\mathbf r\), and \(\mu^+\) is the mean of the positive values within \(\mathbf r\).
Note
This method can fail to fit data containing positively-skewed noise. A potential fix is to apply a log-transform to the data before calling the method to make the noise more normal-like, but this is not guaranteed to work in all cases.
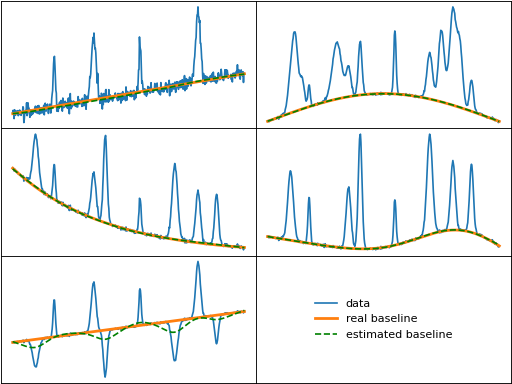
lsrpls (Locally Symmetric Reweighted Penalized Least Squares)
lsrpls() uses a single weighting function that is designed to account
for noisy data. The weighting for lsrpls is nearly identical to drpls, but the two differ
in the minimized function.
Minimized function:
Linear system:
Weighting:
where \(r_i = y_i - v_i\), \(t\) is the iteration number, and \(\mu^-\) and \(\sigma^-\) are the mean and standard deviation, respectively, of the negative values in the residual vector \(\mathbf r\).